XML in Arbortext APP
|
XML in Arbortext APP
|
|
|
|
|
SummaryThis chapter covers the use of XML within the Arbortext APP environment, specificaly how it handles the standard and its related technologies. |
1 |
Introduction |
|
This chapter covers the use of XML within the Arbortext APP environment, specificaly how it handles the standard and its related technologies. |
 |
Please note that this document only gives a brief overview of XML. This document is not a comprehensive technical overview of XML. This is because XML is well documented and there are many external resources for learning XML. This document assumes that the reader has some prior knowledge of XML and therefore the purpose is to provide a specific description of XML in Arbortext APP. |
2 |
XML Overview |
|
This section provides an overview of XML, how it can be used and combined with Arbortext APP and an introduction to the XML interface in Arbortext APP. |
|
XML (Extensible Mark-up Language) is a modified dialect of SGML. Extensible means that the language can be extended to meet many different needs. It is also considered extensible because it is not a fixed format language like HTML (a single, predefined mark-up language). Instead, XML is actually a metalaw (a language for describing other languages) which lets you design your own customised mark-up languages for limitless different document types. |
|
XML is an SGML subset, using only the most common SGML features. XML is therefore valid SGML.Some of the main features of XML are shown below: |
|
|
XML is a mark-up language used to structurally annotate information. It is concerned with the logical structure of a document. An XML document is made up of elements in a hierarchical tree structure. Every element has an element type name and can have a set of attributes. |
|
When information has a defined structure it is possible to reuse, reformat and easily locate the information. Structured data also makes it possible to automate a broad range of publishing processes. It is important to remember that XML describes data, it does not do anything with it. XML is not a programming language; it is declarative, not procedural. XML based languages describe information sets that enable you to describe information so that it can be presented and transmitted. Once XML is used to mark up information according to defined vocabularies, the next step is to take control of the information. In order to be able to transform information marked up in XML from one vocabulary to another, the XSLT (Extensible Stylesheet Language Transformation) is also supported within Arbortext APP. For more information see the XSLT in APP chapter. |
|
XML is one tool that may help solve a variety of information problems. When your data is marked-up in XML, it means that you can re-use the same data, using a variety of different transformations. This means that with XML it is possible to reuse text in different documents and formats. Therefore XML is particularly useful if you have at least two different things you want to do with the same information. |
|
The points below describe some of the fundamental benefits of XML: |
|
2.1 |
XML Basics |
2.1.1 |
Elements |
|
XML documents define or tag each piece of information. The tags that define each piece of information are known as XML elements. In XML, you define your own tags. The text between the < > (angled brackets, also known as chevrons) is the name of the element. XML elements have a start tag and an end tag. You must always have an end tag in XML. The end tag has a forward slash after the opening bracket. |
|
The following applies when using XML: |
|
|
Below is a very simple example of a 'marked-up' document: |
|
2.1.2 |
Empty Elements |
|
As well as using start and end tags, you can also use empty tags. An empty tag does not have a closing tag. This is a self-closing element, for example: |
|
<figure/> |
|
is the equivalent of: |
|
<figure></figure> |
2.2 |
XML Structure |
2.2.1 |
The XML declaration |
|
The first line of an XML document is the 'XML declaration': |
|
<?xml version="1.0"?> |
|
The version attribute states the actual version of the XML standard that is being used. |
2.2.1.1 |
Encoding |
|
The encoding attribute is optional in the XML declaration and defines the character encoding that should be used, for example: |
|
<?xml version="1.0" encoding="UTF-16"?> |
Unicode |
|
Unicode is a character encoding that describes the positions of characters in a font for international use and data exchange. Unicode is the default character encoding for XML documents. |
|
If the encoding attribute is not present in the XML declaration, two default encodings are used; UTF-8 and UTF-16. If these encodings are not used, the encoding must be declared in the XML declaration, for example: |
|
<?xml version="1.0" encoding="..."?> |
|
For more information see the Unicode chapter. |
2.2.1.2 |
Stand alone |
|
The XML declaration also has a 'stand alone' attribute which determines whether the XML document has to read an external DTD. If the 'stand alone' attribute has the value 'no', the XML document should read an external DTD. Documents that do not refer to DTD use the 'stand alone' attribute value of 'yes'. |
|
The 'stand alone' attribute is optional in an XML declaration. If it is not present the default is 'no'. |
2.2.2 |
The root element |
|
All XML documents must have a root element. All other elements in the same document are children of this root element. The root element is the top level of the structure in an XML document. |
|
The example below shows the structure and hierarchy of an XML document: |
 |
2.2.3 |
XML Attributes |
|
XML elements can use attributes, for example: |
|
|||
|
The value of an attribute needs to be within either single or double quotes as shown above. |
2.2.4 |
XML Entities |
|
Entities are declared in the DTD. Entity references within an XML document start with the ampersand '&' and ends with a semicolon ';'. In order to use an entity, you reference it by its unique name. |
|
Entities are used to hold content such as XML, plain text, binary code etc. A common use of entities is to hold characters which cannot be used in the XML (such as '<' ('<') and '&' ('&')). Entities can refer to either internal or external data. Entity references within an XML document point to and include the content of the external files. |
2.2.5 |
Document Type Definition - DTD |
|
A Document Type Definition (DTD) describes what is allowed in a document and in what order. A DTD describes elements, attributes, values, entities and parameter entities that can be used to mark-up the information in an XML document. The XML document instance contains marked up text that optionally refers to a DTD. If you want to validate your mark-up structure, the XML instance should be marked up in conformance with that DTD.It is possible to separate a DTD into sub-sections called modules. This can make a DTD easier to edit and understand. |
2.2.5.1 |
Internal and External DTDs |
|
It is possible to have both internal and external DTDs: |
|
2.2.6 |
XML Schemas |
|
An XML Schema is an alternative to a DTD. Similar to DTDs, Schemas define document structure and content type of XML documents. Unlike DTDs, Schemas are an XML language. |
|
Up to and including version 8, Arbortext APP does not support internal validation against schemas. |
2.2.7 |
XML Parsing |
|
A parser checks if an XML document is well-formed. It also checks if an XML document conforms to the DTD. If a document conforms to a DTD or Schema it is valid XML. |
2.2.7.1 |
Well-formed XML |
|
An XML document needs to be well-formed. Well-formed means that the document applies to the syntax rules for XML. |
To be well-formed an XML document needs to comply with the following:
|
2.2.7.2 |
Valid XML |
|
An XML document that conforms to the structure laid out in a DTD or Schema is said to be valid. In order for an XML document to be considered valid or invalid it must have a DTD. |
To be valid, an XML document needs to comply with the following:
|
|
For more information on invalid XMLand error messages in Arbortext APP see the Error Reports section. |
2.2.8 |
Document Object Model - DOM |
|
The Document Object Model (DOM) defines the structure of an XML document and the way that XML document is accessed and manipulated. This can be represented by a tree structure. |
|
The DOM describes how an XML parser returns the information contained in an XML document. |
|
For more information on XML tree structures see The XML Tree section. |
2.2.9 |
XML Processing Instructions |
|
Processing Instructions are used to provide information, such as formatting information, to an application. Below is an example of a processing instruction: |
|
|||
|
One example of a processing instruction is the XML declaration, for example: |
|
|||
|
Processing instructions beginning with 'xml' are reserved for XML standardization. |
|
An application can only process a processing instruction that it recognizes, therefore Arbortext APP processing instructions are specific. Below is an example of a Arbortext APP processing instruction: |
|
|||
2.2.10 |
Comments |
|
To make your XML documents easy to read and to understand you can add comments. Comments are made in the same way as in Arbortext APP, for example: |
|
|||
|
XML comments are allowed anywhere inside the character data of your XML document, but they are not allowed inside an element or inside another comment. |
3 |
XML in Arbortext APP |
3.1 |
Parsers and processors |
3.1.1 |
Version 8 - Libxml Parser & XSLT processor |
|
|
|
3.1.2 |
Parsers Pre-version 8 |
3.1.2.1 |
OpenSP Parser |
|
|
3.1.2.2 |
3B2-XML Processing Parser |
|
|
|
|
|
The table below shows the various parsers that have been implemented in different versions of Arbortext APP: |
|
3.1.3 |
Choosing the parser |
|
The old parsers are still present in Arbortext APP, but maintenance will not be continued. In version 8 it is possible to switch between the two XML processing parsers. |
|
It is recommended that you use libxml for new documents created in version 8.00 |
|
For documents created in or after version 8.00, it is possible to switch between the two parsers using the methods outlined below: |
|
To specify the parser that you want to use: |
|
|
All of the options in the Document Preferences dialogue box can also be accessed directly with the fdpref macro using the following syntax: |
|
|||
|
For example, to select the libxml parser enter the following in the macro bar: |
|
|||
|
For more information see fdpref |
|
Other options in the dialogue are detailed in the Options, preference and controls section. |
|
As an alternative to specifying the parser you want to use through the menu and the fdpref macro, it is also possible to use the direct txmlparser macro to toggle between the libxml and 3B2-XML parsers. For more information see txmlparser |
3.2 |
Validation of XML streams |
3.2.1 |
Validation using Internal/External DTDs |
|
It is possible to validate an XML stream against a DTD either internal or external to the Arbortext APP document file. |
|
To specify that you want validate you XML stream against a DTD: |
|
|
When the "Validate against internal DTD" option is selected, Arbortext APP will automatically try and link to the DTD file specified in the System ID part of the doctype statement at the top of your XML stream(s). This file is then used to validate the XML stream. The results from the validation are output to the XML Error stream ("xerror:stream_name"), and the getvar 21885 contains the error code (0 if valid, non-zero if validation failed - use getvar 11886 to get the error message related to the error code). |
|
If the DTD has already been imported or linked in Arbortext APP, then you can use the standard Arbortext APP "{1}stream_name" syntax in your doctype statements to get libxml use the contents of that stream to validate the XML. |
|
For example: Create a file "c:/3d/libxml_dtd_test.dtd" (or equivalent) containing the line. |
|
|||
|
Open a4port.3f (or another template file) in Arbortext APP. In the XML Parser tab in tdpref, select "Validate against internal DTD", Enter the following into "strm0" (deleting the initial "body" tag): |
|
|||
|
Getvar 21885 will return 3 (Validation failed), and the "xerror:strm0" stream will contain |
|
|||
|
You will also notice a link to the dtd file has been automatically created. Now correct the entry in "c:/3d/libxml_dtd_test.dtd" |
|
|||
|
Reload the links (using "tlupdate 1") |
|
Force the XML stream to reparse (select strm0 then "ttagxml") You should now see that getvar 21885 will return 0 (Valid), and the "xerror:strm0" stream is empty. |
|
Note that in the example XML, the doctype could have contained <!DOCTYPE test PUBLIC "fish" "c:/3d/libxml_dtd_test.dtd"> and it still would have worked in the same way. This is because libxml is unable to resolve "fish" to a valid URI (the missing functionality), so falls back to using the System ID instead. |
|
If you just wish to parse the XML to see if it is well formed, then when Arbortext APP detects that a stream contains XML (either by looking for the <?xml ...?> declaration at the top of the stream, or by the stream being an XML (.xm) type) it will automatically check the stream for well formed errors. Any errors from the parser are sent to "xerror:stream_name", and getvar 21881 will contain the error code (0 for well-formed and no errors, non zero for any errors). |
|
Although the standard Libxml library is able to resolve the PUBLIC identifier to an external DTD, support for this feature is not currently activated as of version 8.02a due to qualified user demand priorities. However, it is still possible to validate your XML in Arbortext APP using an external DTD regardless of whether a PUBLIC or SYSTEM doctype is specified. |
|
All of the options in the Document Preferences dialogue box can also be accessed directly with the fdpref macro using the following syntax: |
|
|||
|
For example, to validate against an internal DTD enter the following in the macro bar: |
|
|||
|
For more information see fdpref |
3.2.2 |
Validation on individual streams |
|
The txmlvalid macro allows XML validation on a per stream basis instead of simply per document. |
|
For more information see txmlvalid |
3.2.3 |
Validation on external streams (V9) |
|
You can enable external XML files to be loaded without turning on validation. |
|
For more information see txmlext |
3.3 |
Loading XML streams |
|
To import an XML stream in to Arbortext APP you can use the standard tftext macro, or an individual process menu and macro that has been implemented as detailed below: |
|
|
The corresponding macro for this is txmlload. |
3.4 |
Define Streams as XML |
3.4.1 |
The ttagxml macro |
|
When using the 3B2-XML parser it is only possible to parse '.xm' or '.xs' streams. Using the ttagxml macro you can force a text stream to be parsed as XML. |
|
For more information see ttagxml |
3.4.2 |
The ttxml macro |
|
When using the libxml parser it is possible to use the ttxml macro to define a text stream as a .xm stream. |
|
|
|
This meant that the benefits of XML parsing were not available to other types of stream, for example, auto-generated streams. In order to change this and utilise the benefits that XML offers, the ttxml macro is used to indicate if a stream contains XML and is required to be parsed. |
|
For more information see ttxml |
3.5 |
Saving an XML stream |
|
To save an XML stream to a file: |
|
3.5.1 |
The txmlsave macro |
|
Alternatively, instead of saving an XML document using the menu interface, you can use the txmlsave macro to save an XML stream to a file. |
|
For more information, see txmlsave |
3.6 |
The XML Tree |
|
The elements of the XML document are described as nodes of a tree. In Arbortext APP XML streams are broken down into various component parts, such as type, location, name and value of each piece of data that makes up the XML document. These component parts form what is referred to as the XML tree. |
3.6.1 |
The XML Tree Bar |
|
The XML tree bar is a toolbar that displays information about the XML tree. The XML tree bar is context sensitive and therefore the information that it displays depends on where the cursor is currently positioned within the document. |
|
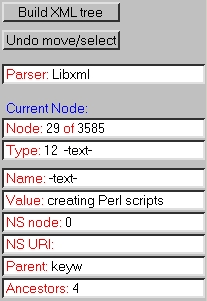
It also provides useful information and functions that you will regularly use when manipulating XML documents. This functionality makes the XML tree bar particularly useful for document editing, retrieval and navigation of an XML document. Below is a screenshot of the top of the XML tree bar: |
 |
|
To enable the XML tree bar: |
|
|
Alternatively, enable the xmltree_bar using the toolbars macro as shown below: |
|
|||
 |
The XML tree toolbar is quite large and due to the current Arbortext APP toolbar limitations, unless you are running a reasonably high screen resolution you may not see the bottom fields. |
|
The following list explains each field in the XML tree bar: |
3.6.1.1 |
Build XML Tree |
|
The 'Build XML Tree' button executes the ttagxml macro. It therefore treats the document as an .xm stream and builds the XML tree which provides the information for the XML tree bar. |
3.6.1.2 |
Undo move/select |
|
The 'Undo move/select' button takes you back to your previous selection in the XML tree bar and highlights the appropriate position in the document. |
3.6.1.3 |
Parser |
|
The 'Parser' button executes the txmlparser macro and therefore toggles between the 3B2-XML and libxml parser. |
3.6.1.4 |
Current Node |
|
The 'Current Node' section provides information about the current node. A node is the term used to define each component part in the XML tree structure, such as element and text nodes. |
|
It is important to note that each node is given a number. This number also includes the DTD (if internal), any spaces and attributes. |
Node |
|
The 'Node' field displays the current node number and maximum node number, for example, 15 of 43. |
Type |
|
The 'Type' field displays the type code of the node name and the name of the node type, for example, 8 -element-. |
Name |
|
The 'Name' field displays the current node name. Click to select the current node. |
Value |
|
The 'Value' field displays the current node value, for example if the content of the text was 'info', the 'Value' field would display 'info'. |
NS node |
|
The 'NS node' field displays the namespace node (code) for the current node. |
NS URI |
|
The 'NS URI' field displays the namespace URI of the current node. Click to select the current namespace URI of the current node. For more information see Make into link XML Namespaces |
Parent |
|
The 'Parent' field displays the name of the parent node of the current node. |
Ancestors |
|
The 'Ancestors' field displays the number of ancestors for the current node. Click to go back in sequence through each of the nodes. |
3.6.1.5 |
Element Position |
Start |
|
The 'Start' field displays the start (character) position of the element. Click to go to the start position of the element. |
End |
|
The 'End' field displays the end (character) position of the element. Click to go to the end position of the element. |
3.6.1.6 |
Content Position |
Start |
|
The 'Start' field displays the start (character) position of the content. Click to go to the start position of the content. |
End |
|
The 'End' field displays the end (character) position of the content. Click to go to the start position of the content. |
3.6.1.7 |
Siblings |
Before |
|
The 'Before' field displays the number of sibling nodes before the current node. |
1st |
|
The '1st' field displays the first sibling name. Click to select the first sibling name. |
Next |
|
The 'Next' field displays the next sibling name. Click to select the next sibling name. |
Previous |
|
The 'Previous' field displays the previous sibling name. Click to select the previous sibling name. |
Last |
|
The 'Last' field displays the last sibling name. Click to select the last sibling name. |
After |
|
The 'After' field displays the number of sibling nodes after the current node. |
3.6.1.8 |
Children |
1st |
|
The '1st' field displays the first child node name. Click to select the first child node name. |
Last |
|
The 'Last' field displays the last child node name. Click to select the last child node name. |
Number |
|
The 'Number' field displays the number of child nodes. Click to select all the child nodes. |
3.6.1.9 |
Attributes |
1st |
|
The '1st' field displays the first attribute node name. Click to select the first attribute. |
Last |
|
The 'Last' field displays the last attribute node name. Click to select the last attribute. |
Number |
|
The 'Number' field displays the number of attribute nodes. Click to select all the attribute nodes. |
3.6.1.10 |
Namespaces |
1st |
|
The '1st' field displays the first namespace node name. Click to select the first namespace. |
Last |
|
The 'Last' field displays the last namespace node name. Click to select the last namespace. |
Number |
|
The 'Number' field displays the number of namespace nodes. Click to select all the namespace nodes. |
NS Scope |
|
The 'NS Scope' field displays the namespaces that can be used on the current element. |
3.7 |
Error Reporting |
|
When you parse an XML document against a DTD there will be validation errors if a document is not well-formed. |
3.7.1 |
XML Error Streams |
|
Whenever an error is detected the xerror: namespace is created. Arbortext APP creates a text stream of the same name as the stream that is being parsed. This contains the error messages associated with that stream. The error messages have the same name as the XML stream and are of type 'XML Error' (.xe). All errors from the libxml parser will be created in the xerror: namespace. |
3.7.2 |
Well-formed Errors (V9) |
|
When a stream containing XML data is parsed, and internal tree is built in order to allow functionality such as XPath or XSLT to work. In versions of Arbortext APP before version 9.0, this tree was kept for non well-formed data even though it might not contain any reliable content. |
|
In a limited set of circumstances, executing XPath expressions against such a partially built XML tree during formatting can cause Arbortext APP to behave erratically or produce incorrect results without making it immediately obvious that anything might be wrong. |
|
As such, it has become necessary to delete the tree if the data failed to parse correctly. Non well-formed streams will behave as if the XML flag on the stream was turned off, i.e. XPath and XSLT will fail to run. This also ensures that Arbortext APP complies more closely with the XML specification. If the only errors created are due to validation errors and there are not any well-formed errors, then the tree is kept as normal. |
|
If this change in behaviour prevents the document from formatting correctly, then the solution is to ensure that the XML data is well-formed and parses correctly. Should this not be possible, an option is available in document preferences to retain the tree in the event of well-formed errors. |
3.7.3 |
Viewing Parser Errors |
|
To view parser errors: |
|
Select [XML/View Parser Errors] |
|
This invokes the Browse Tags dialogue box showing all of the .xe streams. |
3.7.3.1 |
The txmlerror macro |
|
As an alternative to accessing parser errors through the menu, it is also possible to use the txmlerror macro to view parser errors. |
|
For more information see txmlerror |
3.7.4 |
Saving XML Error Streams |
|
To specify whether to save the error stream with the Arbortext APP document: |
|
3.7.5 |
Error Bar |
|
In order to see the last error code from the libxml parser you can use the libxml error bar: |
 |
|
To enable the libxml error bar: |
|
|
Alternatively, enable the libxml error bar using the toolbars macro as shown below: |
|
|||
|
The following is an explanation of the two fields in the libxml error bar: |
|
3.8 |
Options Preferences and Controls |
|
All of the options in the Document Preferences dialogue box can also be accessed directly with the fdpref and/or direct macros. See also 'Associated Arbortext APP macros and keywords' within the Further information section. |
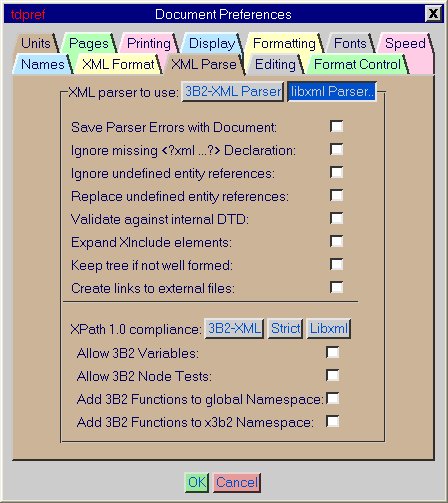
3.8.1 |
Parsing and Controls |
 |
3.8.1.1 |
Save parser errors with document |
|
See Errors section above also xmlparser. |
3.8.1.2 |
Ignoring XML declarations |
|
If the <?xml?> declaration is missing from your XML document the libxml parser will return an error message. However, it is possible to ignore the missing <?xml?> declaration so that you can parse your document. |
|
To specify whether or not the <?xml?> declaration is required or not: |
|
|
All of the options in the Document Preferences dialogue box can also be accessed directly with the fdpref macro using the following syntax: |
|
|||
|
For example, to ignore a missing <?xml?> declaration from a document: |
|
|||
|
For more information see fdpref. |
|
By default the 3B2-XML parser does not require the <?xml?> declaration. However, the default for the libxml parser is that it does require the <?xml?> declaration. |
3.8.1.3 |
Ignoring undefined entity references |
|
Will ignore the error message generated if the XML document contains entity references that are not defined in the specified DTD. |
|
To ignore undefined entities: |
|
|
All of the options in the Document Preferences dialogue box can also be accessed directly with the fdpref macro using the following syntax: |
|
|||
|
For example, to ignore undefined entities: |
|
|||
|
For more information see fdpref. |
|
By default the 3B2-XML parser does not require entity references. However, the default for the libxml parser is that it does require entity references. |
3.8.1.4 |
Replace undefined entity references |
|
If the option to replace undefined entity references is selected, any undefined entity references are preserved as entity references. For example, using XPath to inspect a text node containing "&ent;" and "Replace" is on, then "&ent;" is output instead of "".". See also xmlparser and XSLT in APP. |
3.8.1.5 |
Validate against internal DTD |
|
See parsing section above also xmlparser. |
3.8.1.6 |
Keep tree if not well formed |
|
When libxml encounters well-formed errors, parsing stops and the tree that was being created gets deleted. This ensures that during formatting, anything that requires use of the tree, such as XPath or XSLT, behaves in a reliable and consistent manner. If this option is selected, however much of the tree that was built before the parser error occurred will be preserved. As it is not possible to predict what state the tree might be in at this point, it is possible to get random and undesirable effects in the formatted output. Use of this option is NOT supported, and is only provided for backward compatibility. |
3.8.1.7 |
Load external entity references |
|
By default, when libxml requires access to an external file to load a DTD for example, it will access the file without creating a permanent link to it. As such, every time it needs to reparse the document, it will need to access the file again. Setting this option will create a link to the file when it is first accessed so libxml can read the copy of the file stored by Arbortext APP for each subsequent access. Should the file change on disk, then libxml will not recognise the change until Arbortext APP reloads the linked file. |
3.8.1.8 |
Load external files |
|
This option controls whether libxml is allowed to load external files to resolve entity references or includes without requiring validation to be turned on. This option can be overridden by each stream independently by the txmlvalid macro. |
3.8.2 |
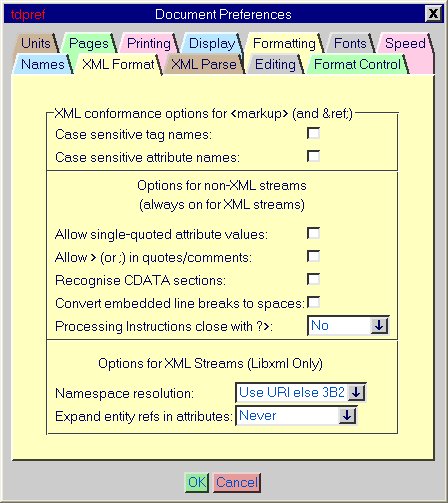
XML Conformance options for markup |
|
The XML Format Conformance options do not relate to the parser, they are associated with the format of the XML. You use these options if you have data of XML structure and you do not want to build the XML tree, but you want to format the data. |
|
All the following format options are accessed through the Document Preferences dialogue box. To invoke the Document Preferences dialogue box: |
|
|
See also xml_conf. |
 |
|
All of the options described below are on by default for XML streams. |
3.8.2.1 |
Case Sensitive Tag Names |
|
To specify that tag names are case sensitive in an XML document: |
|
All of the options in the Document Preferences dialogue box can also be accessed directly with the fdpref macro using the following syntax: |
|
|||
|
For example, to allow case sensitive tag names: |
|
|||
|
For more information see fdpref. |
3.8.2.2 |
Case Sensitive Attribute Names |
|
To specify that attributes names are case sensitive in an XML document: |
|
All of the options in the Document Preferences dialogue box can also be accessed directly with the fdpref macro using the following syntax: |
|
|||
|
For example, to allow case sensitive attribute names: |
|
|||
|
For more information see fdpref. |
3.8.3 |
Options for non-xml streams |
|
Similar to the XML Format Conformance options, the Options for non-xml streams do not relate to the parser, they are associated with the format of the XML. |
|
All the following format options are also accessed by selecting [Document/Preferences/Document] or entering the tdpref macro in the macro bar to invoke the Document Preferences dialogue box. The format options can be found under the |
|
All of the options described below are on by default for XML streams. |
3.8.3.1 |
Allow attribute inheritance |
|
This option allows closing elements and children elements to inherit attributes. This enables the use of Arbortext APP scripting and direct showstring access to retrieve and use the attributes from parent and self elements. |
|
For more information on Arbortext APP scripting see the 3B2 Scripting Chapter |
|
To allow attribute inheritance in non-xml documents: |
3.8.3.2 |
Allow single quoted attribute values |
|
To allow single quoted attribute values in non-xml documents: |
3.8.3.3 |
Special characters in quote comments |
|
To allow > (or ;) in quotes/comments in non-xml documents: |
3.8.3.4 |
Recognise CDATA sections |
|
To recognise CDATA sections in non-xml documents: |
3.8.3.5 |
Convert embedded line breaks to spaces |
|
To convert embedded line breaks to spaces in non-xml documents: |
3.8.3.6 |
XML compliant PIs in non XML streams |
|
To specify whether processing Instructions close with ?> in non-xml documents choose one of the following options as appropriate from the drop down list: |
|
3.8.4 |
Formatting attributes (V9) |
3.8.4.1 |
Attribute Namespace Resolution |
|
When using attribute loops during formatting of an XML stream, it is possible to match on attributes based on the namespace URI instead of prefix in a similar manner to the XML Namespace resolution described above. If the XML document contains the following element: |
|
|||
|
then the only way to match on this attribute in an attribute loop is would be to use the prefix: |
|
|
To use the namespace URI to match the attribute instead of the prefix, then the URI should be placed in square brackets and used instead of the prefix in the attribute label, as follows: |
|
|
The same conditions apply to attribute namespace resolution as to XML Namespace resolution, i.e. the XML stream must be well-formed and have the XML flag set, and one of the two “Use URI” document preferences must be selected. |
|
This option is available from the tdpref dialogue or direct using xmlparser. |
3.8.4.2 |
Attribute Entity References |
|
When Arbortext APP needs to get the contents of an attribute value during formatting (without using XPath), the attribute value is normally returned exactly as it appears in the source XML stream. For example, if the attribute value contained an entity reference, the entity will not get expanded. To allow for this, and to reduce the amount of work the template needs to do to check for possible attribute values, there is a setting in the XML Format tab in Document Preferences to expand any entity references when formatting. Note that this option does not affect the way the XML stream is parsed, so will not change the way XPath or XSLT see the contents of the attribute. |
|
This option is available from the tdpref dialogue or direct using xmlparser. |
3.8.5 |
Editing and working with your XML |
|
Although Arbortext APP was not originally designed as a direct XML editor, depending on your production environment and tool set you may wish to use is for this purpose. If this is the case there are some small items to bear in mind when editing you XML stream to help you especially when using allot of XPath or CALS and MathML mark-up libraries. |
|
When you make a change in an XML stream Arbortext APP builds the XML tree in the background for the whole instance (needed so you XPath can interrogate the tree to get the correct results), so can therefore make Arbortext APP seam very slow to format. To stop Arbortext APP building the tree each time you change you stream simply click the icon in the bottom toolbar |
|
General XML formatting speed can be further enhanced by sensible implementation XPath in your template and combined use of Arbortext APP standard features, i.e. not using XPath for every item possible, for example current node attribute values, instead use token loops that are specifically designed with speed in mind to handle xml attributes. |
3.9 |
URI Handling |
|
As of v8.10u, it is no longer possible to use "{0}strm0" style syntax in URIs when using libxml to parse XML documents or run XSLT stylesheets. Instead, it has become necessary to replace this with a syntax compliant with the XML rules for URI resolution. |
|
Where you need to specify a stream for libxml to access (for example in a DTD, or in XSLT when including external stylesheets), a new URI scheme has been created that will let you access internal streams or areas directly. For example, you will now have to use "x3b2://type=stream/strm0" instead of "{0}strm0". This change only affects the use of filenames where libxml is required to access the file and does not change existing Arbortext APP functionality. |
|
The syntax for the URI scheme is as follows: |
|
|||
|
where parameters specifies the type of area or stream to open, i.e. what used to be allowed inside the {}, and filename is the name of area or stream, i.e. what came after the {}. The table below shows the list of valid parameters. |
|
|
The encoding parameter shown in the last example will be ignored if used on a URI that refers to a stream instead of a file. In order to access streams in namespaces, it is possible to refer to the namespaces as if they were directories, for example, use "x3b2://type=stream/ns/openme" instead of "{0}ns:openme". Although it is perfectly valid to keep using colons as namespace separators, mapping the namespaces to directories allows you to take advantage of extra functionality such as relative path resolution or XML Base, letting you change namespaces mid-document for example. |
3.10 |
Relative Path Resolution |
|
In order to provide a strict method for resolving any relative paths provided to libxml through URIs, a new macro and area has been created that allow you to specify a stream level base URI for libxml. |
|
It is possible to set the base level URI for a stream with the tsbaseuri macro. This takes the following parameters: |
|
|||
|
This base area can then be accessed anywhere throughout Arbortext APP by using a new area of the form {~strm} where "strm" is the name of the stream to get the base path from. The equivalent URI in libxml is "x3b2://type=strmbase;name=strm/". It is also possible to set a global default across Arbortext APP by putting the base path into a system variable "^_libxml_system_base", although this method is not recommended as it is not unique to each document. |
|
When libxml is required to resolve a relative path, it picks the first valid URI it finds checking the following things in order: |
|
|
Note that if 2) contains an encoding in the URI (e.g. {:xml-auto}),the encoding will be ignored when calculating the new filename, and will need to be re specified in the new URI if still required. |
|
If for some reason these rules do not result in a valid absolute URI, then an error will be generated. However, as the final step resolves to the directory the document was opened from, this is unlikely to happen. The area "{~}" (or "x3b2://type=strmbase/") follows these rules to calculate whichfinal URI to resolve to. |
3.11 |
XML Base |
|
Should the base URI need to change in the middle of the XML document, it is possible to override the standard path resolution steps using XML Base. To make use of this, specify an attribute xml:base="/path/" on the required element, and any relative URIs specified on child elements will try and resolve to this path first before following the standard rules. |
3.12 |
Filenames in libxml |
|
In versions of Arbortext APP prior to 9.0, it was possible to use standard APP curly bracket syntax in filenames in XML documents. In order to restore compliance with the XML specification and to give access to new functionality, it has become necessary to replace this with a valid URI style syntax. |
|
Wherever a filename is specified that libxml will need to access, for example in a DTD or loading external XSLT stylesheets, the new URI scheme should be used to provide access to internal streams or areas directly. For example, to access a stream "tx1", the filename should now be "x3b2://type=stream/tx1" instead of "{0}tx1". This new URI scheme does not need to be used if the filename did not prevviously require use of curly brackets, for example "c:\xml\doc.dtd" is still permissible. |
|
This change only affects filenames inside libxml, i.e traditional curly bracket syntax is still allowed to be use in Arbortext APP outside of XML parsing. |
|
The syntax for the URI scheme is as follows: |
|
|||
|
where parameters specifies the type of area or stream to open, i.e. what used to be allowed inside the { }, and filename is the name of the area or stream, i.e. what came after the { }. The ’/’ between the parameters and the filename is only used to mark the end of the parameters and does not form part of the filename. Should the filename need to start with a ’/’ then an extra forward slash is required in the filename, i.e. “x3b2://encoding=utf-8//demo.3d” instead of “{:utf-8}/demo.3d”. |
|
The table below shows examples for the different types of curly bracket filenames. |
|
|
In order to access streams in Arbortext APP namespaces, it is possible to refer to the namespaces as if they were directories, for example use “x3b2://type=stream/ns/openme” instead of “{0}ns:openme”. Although it is perfectly valid to keep using colons as namespace separators, mapping the namespaces to directories allows access to extra functionality such as relative path resolution or XML Base which can be used to switch namespaces mid document in a similar manner to the nameup and namedown processing instructions. |
3.13 |
Catalogs (V9) |
|
XML Catalogs provide a mechanism for mapping from a unique identifier to a URI reference, and are used primarily to access DTDs and entity declarations. For example, if the DOCTYPE declaration in an XML document contains the following: |
|
|
Then libxml will be able to inspect the catalog file associated with the XML document and look up the entry matching the Public identifier to get the URI containing the required entities. Specific details on how to use Catalogs can be found from the Catalog entry in the glossary. |
|
To associate an XML stream with a catalog, there is a macro txmlcatalog which will attaches the location of the catalog file to the stream so libxml can access it during parsing. Only one catalog file can be used per stream. If no catalog file is available, then libxml will first check the contents of the variable "^_cl_xmlcatalog" to see if this contains a path to a valid catalog file, other wise it will attempt to use normal relative path resolution to try and work out which file it needs to access to find the correct DTD or entity declaration. |
|
See also txmlcatalog. |
3.14 |
XML Getvars |
|
The following getvars can be used to obtain information regarding the state of the XML parser, or the XML tree produced from the parser. $21881v returns the last error code for the XML parser, and will be 0 for success, non-zero for failure. $21883v returns the error code from the previous XSLT processing and again is 0 for success, non-zero for failure. $11882v and $11884v return a textual error message for the specified error code for the XML parse and XSLT processing respectively. |
|
Any errors arising from validation are still output to the same error stream as fromparsing, but the getvars $21881v and $11882v only show well-formed errors.$21885v and $11886v show errors arising from the validation. |
3.14.1 |
Parser status |
|
|||||||||||||||||||||||||||||||
3.14.2 |
Node ID at positions |
|
||||||||||||||||||||||||||||||||||
3.14.3 |
Numeric node information |
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
3.14.4 |
Text node information |
|
||||||||||||||||||||||||||||||||||||||||
4 |
Namespaces |
4.1 |
XML Namespaces |
|
XML namespaces provide unique element and attribute names to avoid clashes of the same element or attribute in XML documents. |
|
XML namespaces enable the following: |
|
|
XML enables people to define their own elements (to create their own tags). This means that XML documents can contain different and multiple mark-up vocabularies. Potentially, a name conflict could occur if documents use the same name to describe two different types of element. It is possible that elements clash or have different meanings in different circumstances. This can often cause difficulties of recognition and duplication between the elements, which in turn means that the XML can not be processed as desired. |
|
For example, there could be two occurrences of the element <title> and four occurrences of the element <body> within the mark-up of an XML document all within different contexts or parent elements and all requiring different formatting. Arbortext APP can already deal with these publishing problems, but the use of XML namespaces standardises this practice. |
|
A simple way to think of namespaces in Arbortext APP is as folders at the root of a drive in which you place and organise your elements, attributes etc. |
|
Namespaces are used to uniquely identify and define the context of an element so that processing is easy. Namespaces define the hierarchy of elements in an XML document by attaching a desired prefix to each element. |
|
The W3C namespace specification states that the namespace prefix should be a Uniform Resource Identifier (URI). A URI is a short string that identifies resources on the Internet, for example, documents, images, downloadable files, services, electronic mailboxes and other resources. The most common URI is the Uniform Resource Locator (URL) which identifies an Internet domain address. |
|
The purpose of the URI is to give the namespace a unique name. Default URIs can also be provided for elements that don't have a prefix. Standard URIs identify elements from many XML applications. The namespace attribute is placed in the start tag of an element. In Arbortext APP, namespace identifiers can take any format you choose, but it is important to remember that they are case sensitive. |
|
Namespaces enable processing software to recognise tags and attributes quickly and via a standard method. For example, some XML documents contain mark-up from multiple XML applications (an XML document may contain MathML mark-up) and namespaces enable you to differentiate between elements and attributes of the same name. Namespaces also make it possible to group all related elements and attributes from a single XML application together so that processing software can recognise them easily. |
4.2 |
Arbortext APP Namespaces |
|
Arbortext APP namespaces are different from XML namespaces. Arbortext APP namespaces just use a prefix to differentiate between elements. In contrast, XML namespaces use a prefix that is associated with a URI to identify element and attributes. |
|
A Arbortext APP namespace is a named collection of various types of Arbortext APP tags. A namespace is a container for other tags. In Arbortext APP, namespaces work along the same principle as directories or folders and share many of the same characteristics, such as: |
|
|
For more information see the 3B2 Namespaces chapter. See also tnorder, <?nameup>, and <?namedown> commands. |
4.3 |
Using Namespaces with the 3B2-XML Parser |
|
The 3B2-XML parser only uses Arbortext APP namespaces. |
4.4 |
Using Namespaces with the libxml Parser |
|
The libxml parser uses both Arbortext APP namespaces and XML namespaces. Using the libxml parser it is also possible to assign a URI to Arbortext APP namespaces. |
|
The XML document must be well-formed to use XML namespaces. If the document is not well-formed, Arbortext APP will default to using Arbortext APP namespaces. For further information see Make into link Namespaces Resolution below. |
4.4.1 |
The tnsuri macro |
|
The tnsuri macro enables you to assign a URI to a Arbortext APP namespace. You specify the name of the existing Arbortext APP namespace and the name of the URI you wish to assign to it. |
|
The tnsuri command is only available when using the libxml parser. |
|
For more information see tnsuri |
4.4.2 |
Namespaces Resolution |
|
To specify the type of namespace resolution that you want to use: |
|
|
All of the options in the Document Preferences dialogue box can also be accessed directly with the fdpref macro using the following syntax: |
|
|||
|
For example, to specify XML namespaces: |
|
|||
|
For more information see fdpref. |
|
5 |
XInclude (V9) |
|
The purpose of XInclude is to allow a method for modularising XML documents without relying on external entities. It also provides a way of including fragments from existing XML documents using XPointer, and specifies a fallback method in case the document being included is not available. More information on using XInclude can be obtained from the specification and the W3C web site. |
|
To activate XInclude, select the option in the Document Preferences. Any XInclude elements contained in the document being parsed will then get expanded to include the relevant XML. Note that this expansion only occurs on the internal tree stored with the stream, i.e. the complete document is available through XSLT or XPath, but the stream itself does not get altered directly. The normal rules for resolving relative paths still apply, and can be used along with XML Base. A simple example showing how to use it is included here for reference. |
|
Source XML: |
|
|||
|
tx1 Stream (to be included): |
|
|||
|
Result tree after XInclude processing: |
|
|||
|
Source XML using XPointer to select a document fragment: |
|
|||
|
Result tree after XInclude processing: |
|
|||
6 |
Event-based Parsing - SAX |
|
In order to provide a method for handling large XML files without parsing them and having the overhead of storing a tree internally, it is possible to use an event based model to parse the file, called SAX. |
|
This can be found in the txform dialog. The basic principle of a SAX parser is that it reads through the XML document but does not parse it and does not build an XML tree. Instead it throws events every time it finds something in the XML document i.e. "I’ve found an element" or "I’ve found some text" etc. So for example, if the source document contains... |
|
|||
|
the SAX parser will generate the following events: |
|
|
As the SAX parser does not create a tree, you will be unable to use XPath, XSLT, the XML getvars, etc, against the XML stream unless you have flagged it as XML and let libxml parse it normally. Similarly, any information that might be required during formatting such as the structure of the document should either be stored and maintained by the callback functions, or returned to the output stream. This is because the SAX parser itself has no memory of the document - once the particular event has been raised, any data related to that event is lost. |
|
However, what the SAX parser offers over normal XML parsing is a vastly reduced memory usage and increase in speed due to the tree not being automatically built and reparsed, and an increase in flexibility as it is possible to only retain or handle the specific data you might require during formatting. To use the SAX parser, you need to create a control stream defining which events you are interested in, and the name of the Arbortext APP or Perl mini-script to run when the associated event is raised. Each line in the control stream should be of the form: |
|
|||
|
where callbackname is one of the events you wish to process, and scriptname is thename of the script. If the same callback is listed multiple times, only the lastcallback will be used - all previous entries will be ignored.The input parameters to the script, such as the name of the element found,contents of attributes, etc, will be set into specific variables listed below. Should thescript require any output, the contents of the variable with the same name as thescript will get written into the destination stream specified in the txform dialog. |
|
Two variables are always set regardless of which event gets called - "sax_callback"contains the number of the event that occurred, and "sax_noparams" containingthe number of parameters that are being passed into the function. |
|
All variables are set with a name of the form: |
|
|||
|
where callback and variable are as listed in the table below, for example, |
|
|||
|
|
So for example, if an End Element callback is required, the parameter control stream should contain an entry: |
|
|||
|
and when an end of an element is found in the document, my_script will be run with the following variables set: |
|
|
and the return value (containing data to write to the output stream) should bestored in a variable of the same name as the script, i.e. |
|
|||
7 |
XML output driver |
|
From version 9 a new XML output printer driver has been introduced. This driver works in a similar way to the HTML driver in representing the page in XML as it looks on screen, so the text content need not have any markup or structure itself. |
|
The output XML includes general page item and text semantics and conforms to the 'xsml.dtd' located in the Arbortext APP system directory. |
|
Some output options are available when using this driver and these are accessed via the tprint dialogue, or directly using the predefined system variables as detailed in |
 8.00
8.00