XPath in Arbortext APP
|
XPath in Arbortext APP
|
|
|
|
|
SummaryThis document details the technical details required to use XPath statements in Arbortext APP. |
1 |
Introduction |
|
This section is designed to introduce XPath and its power when combined with Arbortext APP. It covers the fundamentals of XPath and how it is incorporated with Arbortext APP in order to provide an easy, concise and practical tool for developing projects. This section also supplies the information needed to build customised XPath expressions and demonstrates how XPath can be used to address an XML document as required. However, this section is not a full XPath manual. XPath is a standard and the full specification is widely available in books and online at www.w3.org/TR/xpath. It is assumed that the reader is familiar with Arbortext APP and it is recommended that you read the XML chapter before reading the XPath chapter. |
1.1 |
What is XPath |
|
The XPath language was created in order to fulfil the operational needs of XSLT, the XSL transformation language, and XPointer, a method to address fragments of external XML documents (see <?xpointer>). Both needed a method of addressing parts of an XML document using standardized syntax. However it must be noted that XPath only addresses the core functionality in these standards as they are not identical. Consequently, Arbortext APP uses XPath as a foundation and uses uniquely developed extensions to address XML documents. XPath is a recommendation of the World Wide Web Consortium (W3C). |
1.2 |
Why XPath in Arbortext APP |
|
The addition of the XPath syntax greatly enhances Arbortext APP, allowing template creation and design to be simple and quick. XPath can be used to gain information about context, to test for the occurrence of particular elements, attributes and text and also to locate and address all parts of the XML instance. |
 |
XPath usage minimises the need for counters, yanks and other show string expressions as each test or manipulation can be performed when and where it is required. |
2 |
Expressions |
|
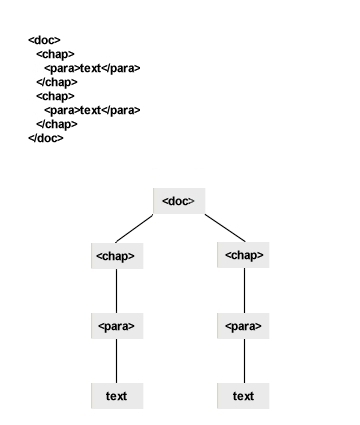
XPath treats an XML document as having a tree structure. To illustrate this the image below shows a simple XML instance and its tree structure representation: |
 |
|
XPath uses genealogical terms to describe the levels of the tree relative to either the root of the document or the currently selected point, for example in the above example, <doc> is the 'parent' of <chapter>. |
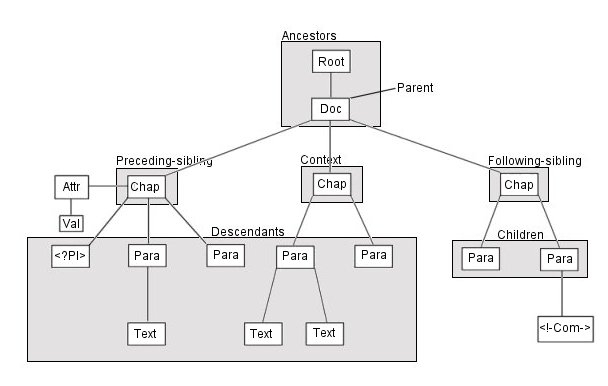
Additionally, in the tree structure there are seven node types for each type of construct that can appear in an XML document:
|
|
Below is an example of a tree structure that demonstrates six node types. The Doc, Chap and Para nodes are elements. |
 |
|
The key to addressing parts of an XML document is the location path. A location path describes how something may be found. By way of analogy, you can think of a location path as describing where a certain paragraph is in a document, for example, "the second paragraph in the third chapter". |
|
The context node is where you are in a document. A location path consists of one or more location steps separated by a slash '/' and can be considered as similar to describing a directory structure. The context node for each step is the result of the previous. |
|
An XPath location step consists of a minimum of two parts; the axis and the node-test. It can also have an optional third part; the predicates, for example: |
|
|||
|
The double colon separates the axis from the node-test and the predicate is encoded in square brackets. The * at the end indicates that there can be zero, one or more than one predicate. |
2.1 |
Expression components |
|
A node-test identifies a type of node in the document. Usually, it is the name of the element but it may also be a function that identifies a node type. The axis distinguishes between these node-tests: child::para finds the para elements that are children of the context node while preceding-sibling::para finds the preceding para elements that are siblings of the context node. |
|
Below is a list of the axes and node-tests available in the XPath language to be used when making XPath expressions. |
2.2 |
Axis values and node-tests |
|
|
A node-test selects a set of nodes using the chosen axis. The principal node type (attribute, namespace or element) of the contaxt node affects the node-test. |
|
|
The axis and the node-test together form the 'basis' of the location step. |
2.3 |
Predicates |
|
A predicate is an expression which filters a node set with respect to an axis to produce a new node set. Here are a few examples: |
|
|
Given the combination of location steps we did in the previous section, we can now add a predicate to one of the steps as follows: |
|
|||
|
which effectively retrieves the id attribute of the first two <chap> elements. |
|
Predicates can be combined with the result of the previos predicate and passed to the next, for example: |
|
|||
|
First selects the third para child, then tests if its ID attribute equals "something". |
2.4 |
Examples of axis values |
|
Below is an example of a basic XML document. |
 |
|
The shaded area shows the current context. |
|
This location step, using the child axis: |
|
|||
|
would point us to the para element. |
|
The parent axis used like this |
|
|||
|
would point us to the root element folder of the XML document. |
|
The ancestor axis used like this |
|
|||
|
would point us to the root element folder of the XML document. |
|
The descendant axis used like this |
|
|||
|
would point us to the para element with element content "Second paragraph". |
|
The attribute axis used like this |
|
|||
|
would point us to the id attribute. |
|
With this basis, the location steps can now be combined. Using the example XML document above, we will use an XPath expression to point to the chap ids. The first step is to start to create the context node by assigning it to the root. This is accomplished by starting an XPath expression with / (slash) character which is the abbreviated syntax for the node tree root. |
|
|||
|
Next we then need to step to its children nodes or nested chap elements. This we can do using the child axis as in: |
|
|||
|
Now the final step would be to use the attribute axis to point to the id attributes as in: |
|
|||
|
These three steps can effectively be combined together by placing a / in between the location steps. |
|
|||
|
This is similar to the method used to describe directory structures in Unix. |
2.5 |
Functions |
|
XPath functions can be used to manipulate or test the node-set which are the results of the location path. |
|
There are four categories of functions: node-set, string, number and Boolean functions. |
2.6 |
Node set functions |
|
2.7 |
String functions |
|
String functions operate on nodes as text and allow comparisons, concatenation and manipulation. String functions simplify tasks which would usually involve complicated yanks, show strings and mini-scripts. |
|
2.8 |
Number functions |
|
Number functions deal with numerical values and allow mathematics to be performed within expressions. |
|
2.9 |
Boolean functions |
|
Boolean values are true and false. We have already seen that these can be converted to their numerical equivalents. It is therefore possible to test if something exists, test its content etc. and get a simple result. There are two functions worth mentioning. |
|
2.10 |
Abbreviations |
|
XPath allows for some of the more commonly used parts of an expression to be abbreviated to help readability and compactness. Some examples are given in the following list. The important ones are that the axis child:: can be omitted and that attribute can be abbreviated to "@". The parent of the context node can be abbreviated to ".." while "." selects the context node. The last one is that [position()=5] can be abbreviated to [5]. |
|
2.11 |
Operators |
|
When performing tests and evaluations, a number of operators are permitted within XPath. |
|
3 |
XPath in Arbortext APP |
|
The XPath processor in Libxml is fully compliant with the W3C XPath 1.0 specification. (for more information on parsers see the XML in 3B2). XPath can be used in Arbortext APP to query and return parts of a document as inline commands, in show strings or in scripts. |
|
Used inline, XPath can display the results of the expression and it can also pass information to variables and tags using the normal Arbortext APP syntax. An XPath expression is called using the <?xpath> keyword with the syntax below: |
|
|||
|
In this example and with all the following examples 'expression' is an XPath expression. |
|
This simply outputs the result where the expression is placed. The result of an expression can be assigned to a variable or string in the same way as it would be with show strings, by placing the target before the expression. For example to pass the result to a variable called "string": |
|
|||
|
XPath expressions can be used in show strings and scripts and, as they access information in memory (the document tree), they can be treated as variables using the syntax: |
|
|||
|
Or in a function variable as: |
|
|||
|
Note the exclamation mark and quotes. For example the following syntax tests the result of an expression against the x(1) counter to produce the OUTPUT if they match. |
|
|||
|
Also, in a script, the following compares a variable value with that returned by the XPath expression and performs a similar action to that above: |
|
|||
3.1 |
Options and preferences |
|
In order to integrate XPath into Arbortext APP more effectively,many enhancements have been made described in the following sections. |
|
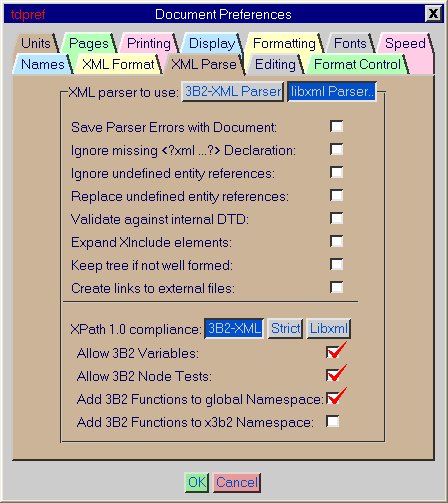
Each of these enhancements are controlled by options under the |
|
By default all these options are off, ensuring that only valid XPath statements are used. It is possible to return to this default by pressing the |
 |
|
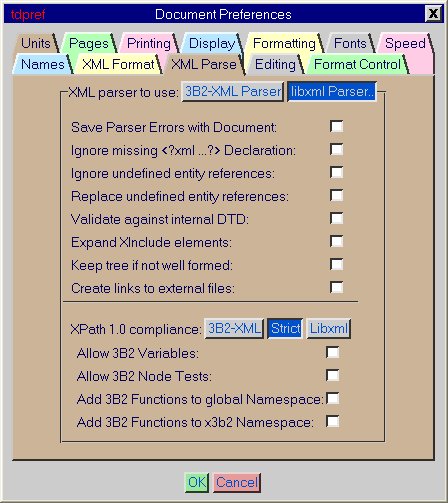
If you want to use the 3B2-XML options, press the |
|
 |
|
If you want to use the libxml options, press the |
|
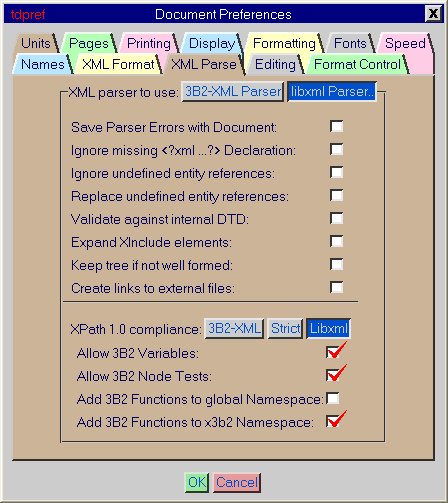 |
|
Alternatively, you can tick the options you require individually. For information about the different parsers in Arbortext APP see the XML in 3B2 chapter. |
|
One enhancement that is not controlled by an option is the ability to double up quote marks. In order to allow quotes to be used inside XPath statements, it is possible to put two quote marks together, which will place a single quote mark in the string, for example: |
|
|||
|
The above syntax will output "hello 'World'". |
3.1.1 |
Allow Arbortext APP variables in XPath statements |
|
It is possible to access the contents of Arbortext APP variables in any place the XPathspecification allows XPath variables. Arbortext APP variables are accessed using the ^character, followed by the variable name. For example: |
|
|||
|
will output "hello". It is also possible to extend this to evaluate dynamic XPathstatements, as follows: |
|
|||
3.1.2 |
Allow Arbortext APP node tests |
|
Three extra node tests have been added to select nodes containing either text, whitespace, or CDATA sections. These can be used in addition to the existing node test functions. These are: |
|
3.1.3 |
Add Arbortext APP functions to global Namespace |
|
A set of extension XPath functions have been added that can be used wherever normal XPath functions can be used. This first option places the extension functions in the global namespace, i.e. you can use the functions as normal functions without specifying any namespaces. This option is only present for backward compatibility, and should not be used when creating new XML documents. |
3.1.4 |
Add Arbortext APP functions to x3b2 Namespace |
|
A set of extension XPath functions have been added that can be used wherever normal XPath functions can be used. This second option places the extension functions in the x3b2 namespace. In order to use these functions, you must prefix them with "x3b2:". As this results in the most compliant XPath usage, this is the preferred option. This option is also required to be selected to use the custom extension functions described below, and to enable the EXSLT extension functions listed in the EXSLT section below in their respective default namespace. If both options are turned off, the Arbortext APP extension functions are not available at all. See the XPath custom functions section for more information. |
3.1.5 |
Context text stream or text blocks |
|
Added ability (v8.11o) to change the XPath context stream when formatting textfrom a different stream. Added ability to select blocks of text during formatting based on XPathexpressions, in addition to the existing start/end character positions. |
|
|||||
|
|||||||||
3.1.6 |
EXSLT functions in XPath |
|
(v8.11) Ability to use exslt functions in XPath expressions. Need to use the default namespace for the relevant set of EXSLT functions. For example, to use the common functions, prefix the function name with ‘exsl:’, for the date functions use ‘date:’, for dynamic use ‘dyn:’, for math use ‘math:’, for sets use ‘set:’ and for strings use ‘str’. |
3.2 |
Special node tests and functions |
|
Extra functions were added to Arbortext APP in order to allow XPath to execute commands specific to Arbortext APP, such as show string like functions, gathering content and mark-up and finding the start and end positions of nodes. These Arbortext APP specific operators are listed in the following table. |
|
The use of the Arbortext APP functions is controlled by two options in the |
|
The second option places the extension functions in the x3b2 namespace. In order to use these functions, you must prefix them with "x3b2:". As this results in the most compliant XPath usage, this is the preferred option. If both options are turned off, the Arbortext APP extension functions are not available at all. |
|
For further information on namespaces in XML, see the see the XML in 3B2 chapter. |
|
|
The commands above are classed as node tests because they are not affected by the x3B2 namespace prefix. |
|
3.3 |
XPath Formatting (V9) |
|
Previously, the primary method to include a fragment of text from a different stream during formatting was by using the following method: |
|
|||
|
which would, for example, format the text from stream tx1 between character positions 30 to 50. The problem with this is that if the contents of stream tx1 changed, then the character positions might no longer refer to the correct places in the stream and would need updating. |
|
This method has been extended to allow XPath or XPointer expressions to select the content from the stream to be formatted. To use an XPath expression, an exclamation mark (!) should be placed after the ’#’, followed by a valid expression that returns a node-set. To use XPointer, then two exclamation marks are required. |
|
For example; |
|
|
This will find all item nodes in tx1 and format them, including the start and end elements, i.e. all text between the start-pos() and end-pos() for each item node returned by the location path. |
|
Placing a dash (-) after the # will only select the contents of the nodes, for example: |
|
|
This will find all item nodes in tx1 and only format the contents of the nodes, i.e. between content-start-pos() and content-end-pos(). |
|
Placing a plus (+) after the # will switch the XPath context to the node being formatted, so that any XPath expressions occurring in the stream will behave as if they were the main stream being formatted. For example: |
|
3.4 |
XPath Custom Functions (V9) |
|
If the option to add the extension XPath functions to the x3b2 namespace isenabled, then it is possible to treat any Arbortext APP or Perl mini-script as a special customextension function. This allows XPath to perform tasks not normally possible, ordifficult to achieve, such as string manipulation or complex calculations.In order to enforce compliance with the relevant specifications, the customfunctions are always only available through the x3b2 namespace, even if the"global namespace" option is selected. |
|
Apart from setting the "x3b2 namespace" option and creating the required script,no further initialisation is required. When processing the XPath expression, if afunction is called that doesn’t exist, then libxml will check to see if a script exists in Arbortext APP with the same name (ignoring the x3b2 prefix). If it does, then this script iscalled, otherwise an error occurs as normal. Note that the pre-defined extensionfunctions take priority over any custom functions, so the scripts should be namedto avoid conflict with the existing functions. |
|
In order to pass parameters into the mini-script and receive a return value, a set ofstandard Arbortext APP variables are used. Each parameter is stored in a variable of the form |
|
|||
|
where "funcname" is the name of the function, and "x" is the number of theparameter. The total number of available parameters is placed in the variable |
|
|||
|
and the result of the function should be placed in the variable of the form |
|
|||
|
again, where "funcname" is the name of the function. |
|
For example, if the following XPath expression was evaluated, |
|
|||
|
then a Arbortext APP miniscript called property will be executed with the parameter "lineheight"placed into a Arbortext APP variable "property_1". As there is only one parameter,the variable "property_n" will contain the value 1. |
|
The result of the script shouldbe placed in a variable called "property". This value will then be used in theremainder of the expression and therefore multiplied by 2. |
|
All input parameters, including node sets, are automatically converted as if theywere passed to the string() function first. Care should be taken to ensure the returnvalues are in the correct format for the rest of the expression. So in the previousexample, if the property script returns a string, then XPath will be unable tomultiply it by two and will not produce a valid result. |
3.5 |
XPath Namespaces (V9) |
|
As a short-cut when using location paths to select nodes in namespaces, it is possible to embed the XPath statements in an XML stream that declares the required namespace. For example, |
|
|
will count all “elem” elements in the tx1 stream that are in the namespace “http://random.com/ns”. Note that the XPath stream must be well-formed XML, and the namespace must be declared with a prefix — default namespaces are ignored. |
4 |
Arbortext APP XPath examples |
|
Below are some simple examples of how to perform tasks which would usually involve show strings in Arbortext APP. |
4.1 |
Lists and numbering |
|
|||
|
outputs the number of preceding siblings called <list_item> plus one. This can be used to number lists, chapters, sections – anything where the number depends on the number of elements of the name which come before the current element. It is necessary to add one because the preceding-sibling axis returns the number of <list_item> elements which come before the current one. |
4.2 |
Context Jump |
|
|||
|
Jumps to the label whose name is the same as the parent of the current element. This is useful for formatting paragraphs depending on how they are nested. |
4.3 |
Boolean context jump |
|
|||
|
Jumps to the label <?:true> if the first <body> element in the document has an attribute columns="2". |
4.4 |
Add attribute values and show to variable |
|
|||
|
Adds up all the colwidth attributes of the cell children of the current element and puts the result into a variable called "width". If placed at the beginning of a table row, it would give you the total width of the row. |
4.5 |
If not first of kind |
|
|||
|
Outputs an &emspace; if there is more than zero preceding <para> elements (i.e if it is not the first in a section). |
4.6 |
Output if "tag" starts with the text "section" |
|
|||
|
This tests if the first <title> child of the context node starts with word 'section'. The result is changed to a number which is compared with the value stored in x(1) to determine whether to output 'New' or not. |
|
This allows the value of x(1) to be varied contextually. Note the use of single quotes around "Section". This is to avoid confusion with the use of double quotes around the XPath expression. |
4.7 |
Combine/display values using concat-nodes |
|
|||
|
This outputs all the id attribute values and separates them with a comma. This is the same as the showstring plus "destination" command but without the need for a variable. This can be very useful for generating the content of TOC's. |
4.8 |
Count descendants of a stream from a script |
|
|||
|
This XPath expression can be used in a script. This example counts all the Chapter descendants of the Arbortext APP XML stream called "stream". This is then passed to the variable ^chapter. You can select the stream you want by prefixing the location path with the stream name and a hash symbol. |
|
The ability to use XPath in Arbortext APP scripts adds even more scope and ease in manipulating and creating complex documents in Arbortext APP. The XPath expressions which have been covered in this chapter can be used as normal in scripts with a slight change in syntax. From the examples above, note that the only change to the syntax is the removal of the chevron and question mark similar to normal Arbortext APP commands in scripts. |
4.9 |
Arbortext APP variables in XPath |
|
Variables can be incorporated into XPath in Arbortext APP. |
|
To pass the results of an XPath command to a variable, any of the command structure in the following examples can be used. |
|
This will find the name of the first descendant and place it into the variable: |
|
|||
|
This command first finds all element descendants of the root. Then it tests if its position is equal to the value stored in ^var. Finally, the name() function returns the name of the element. So in total, it returns the name of the elements at a position equal to the number stored in the variable ^var: |
|
|||
|
This command does the same as the one above but it is easier: |
|
|||
|
This joins the contents of ^var onto the end of 'some text'. |
|
|||
|
This outputs the contents of the variable as a string: |
|
|||
4.10 |
Setting context node at a character position |
|
By entering the character position in your XPath command allows Arbortext APP to start working from that position as if it is the context node and hence arrives at the end result much quicker therefore providing more efficiency. In the example below, 179 is the character position where the context node is placed effectively. |
|
|||
|
Also if a minus character is entered before the number, Arbortext APP will look for the node position rather than the character position. |
|
|||
|
This feature is only available for use with the libxml parser which is implemented from version 8. For information on the libxml parser, see the XML in 3B2 chapter. |
5 |
Further Information and References |
5.1 |
Associated documentation |
|
 |
If using HTML (online or local) documentation, mouse over the links above for a summary. |
5.2 |
Internet resources |
|
You can find out more on XML and XPath by visiting: |
|
The W3C website www.w3c.org/tr/xpath |
|
The XML website www.xml.com |
6 |
Subject Index |
|
Subject index only applicable to the PDF version. |
Document created on 04-Jan-2002, last reviewed on 03-Oct-2005 (revision 4)
 8.12
8.12